



Another Day Another Model - Part 3
Testing the 8GB Raspberry Pi 5 with LLMs

I recently got an 8GB model of the new Raspberry Pi 5 to compare to the 4GB version. So I hooked it up and started testing. I immediately noticed that the whole system ran faster (booting, the GUI through TigerVNC, etc), so I was excited to see how it did compared to my previous machine learning tests (Machine Vision Object Recognition , LLMs). Sadly, the 8GB model did not perform any faster for Object Recognition with either model I tried. On the 4GB model, Yolov8N still ran about 2 fps. And MediaPipe was still about 17fps. So, on to the LLMs (which you might think I’m crazy for trying on such a low-end system with no GPU). How would they perform?
LLMs on RPi5 8GB using Ollama
Funny thing is, I first tested an LLM on the 8GB by running a local python program that used the Mistral API and it was WAY faster! But no kidding… I was out walking around doing errands really psyched about it, but reflecting more, I realised my mistake. I was not seeing the performance of the RPi5, but seeing the RPi5 running a python program that streamed responses from the Mistral API server (a lesson in file organization and naming!).
The real performance answer depends on the model being tested. With Ollama running orca-mini it was indeed faster. Note that representative timings are hard to come by since they are quite variable. I.e., the time to get to a prompt can take quite some time after startup, and then after typing in a prompt the time to get to the first part of the response can also vary a lot. So with orca-mini, the 4GB model started giving a response to my standard “what is a bird” question within 13-110 seconds. With the 8GB model, it did so in about 10-70 seconds. So, 30% faster?
Running orca-mini LLM

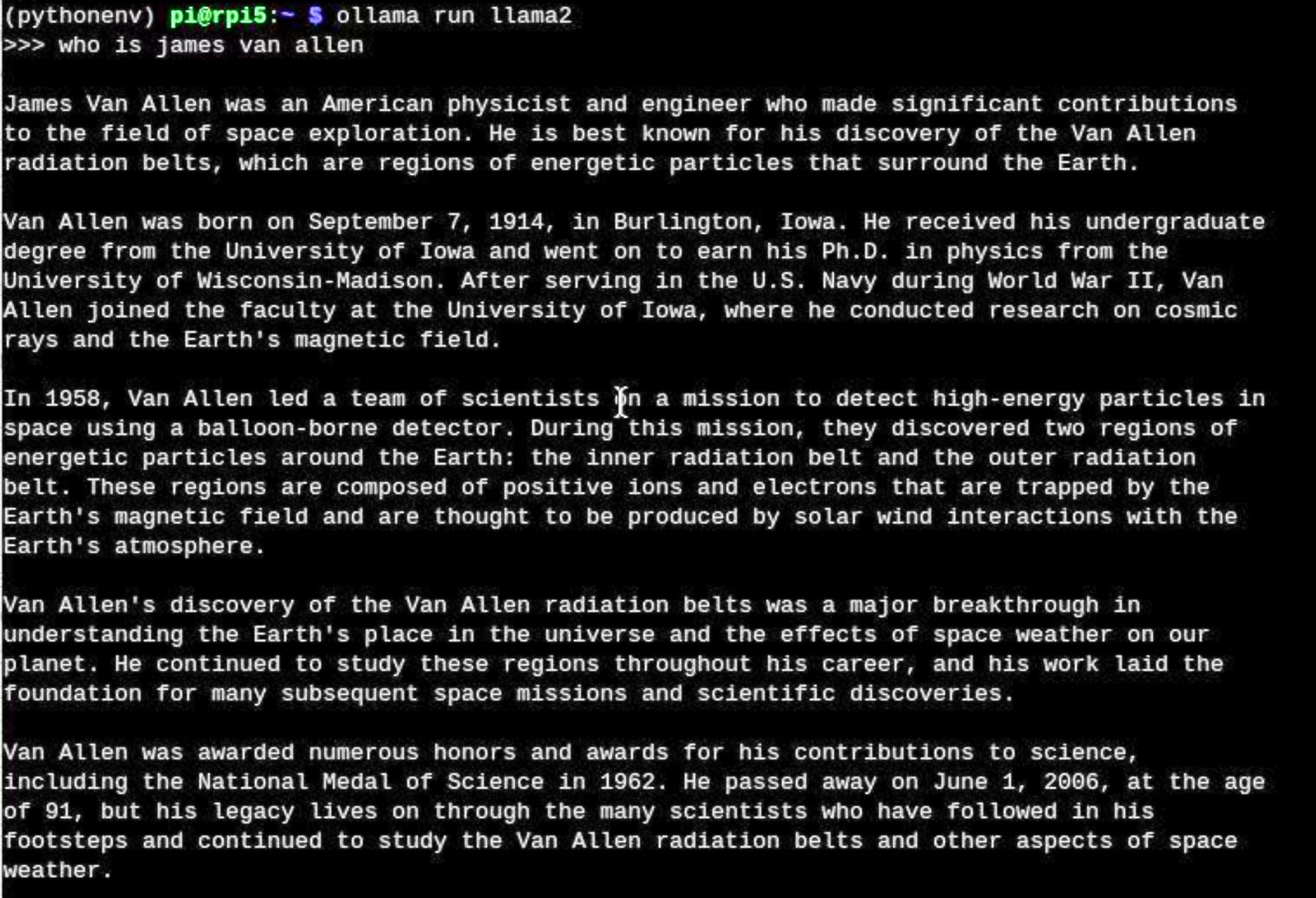
For mistrallite, I tried several times and it acted strangely: e.g. it would stall mid-sentence as it was typing out the response or sometimes crash. Same with the Mistral model, which didn’t crash. Then I tried, just for kicks, to see about other models. I found tinyllama, which seemed to be quite a bit faster — starts in seconds, starts responding to the first prompt in under 4 seconds, and then types out its answers much faster than the other models. Its accuracy was not so up to par though. It thinks the square root of 49 is 5.36. It did give a quite extensive explanation of birds, but in trying my other favorite prompt, it failed miserably.

“Who is James Van Allen” resulted in a bio of an astronaut who flew the Space Shuttle in 2011 — Sorry, but my uncle Jim died in 2006 at 91 (professor emeritus at University of Iowa), discovered the Van Allen radiation belts with an experiment on the first US satellite, and he never went to space. In fact, he felt strongly that human spaceflight was a poor way to spend science money (Is Human Spaceflight Obsolete?).
So yeah, don’t depend on LLMs for accurate information ;~)

With these tests, my conclusion about running LLMs on the Raspberry Pi is that you can do it with a significantly smaller model, but don’t expect great results. The other thing to consider is that the response times are really variable. I don’t fully understand why, but maybe it is because ollama is maintaining context between prompts and that take up memory? I don’t know - maybe one of you can explain?
Try models on a faster platform first
I would recommend that you try out the models on your own computer first (which you can do with Ollama.ai, so you can more quickly assess how they perform for your application without having to wait for the slow RPi5 to respond. For example, on my Mac, tinyllama thinks my uncle was an American actor and comedian, including a role in "The Hangover" trilogy (2011-2013).

So is the 8GB model worth the extra cost (~€23/$20) over the 4GB version?
I’d say yes overall, if only to gain the extra speed for the general system. The 4GB model did quite well for many tasks. But that’s a budget decision for you.
For machine vision and object recognition I’d say no. For LLMs and other memory hungry applications? I think yes. But be careful about the models you try.