



Another Day, Another Model
Testing the Raspberry Pi 5 for ML

Recently I’ve been testing the new Raspberry Pi 5 4GB model for ML.
NOTE: This post and substack replace my previous extra account, which I mistakenly created — please use this new account since I will no longer use the old account.
The 5 is supposed to be MUCH faster than the older 4 version, and I wanted to see how well it could do with ML object recognition. So I started with an Ultralytics model for the RPi, since this is the first one that I found some tutorials for the RPi.
With this model, I was able to get about 2 fps detecting objects with captures from the RPi camera (640x480). But this didn’t seem fast enough, so I kept exploring.

I’ve previously used TensorFlowLite so I went looking for that. But it looks like Google has moved on to something new called MediaPipe as their optimized platform for on-device ML (it works with TFLite models - I used efficientdet.tflite).
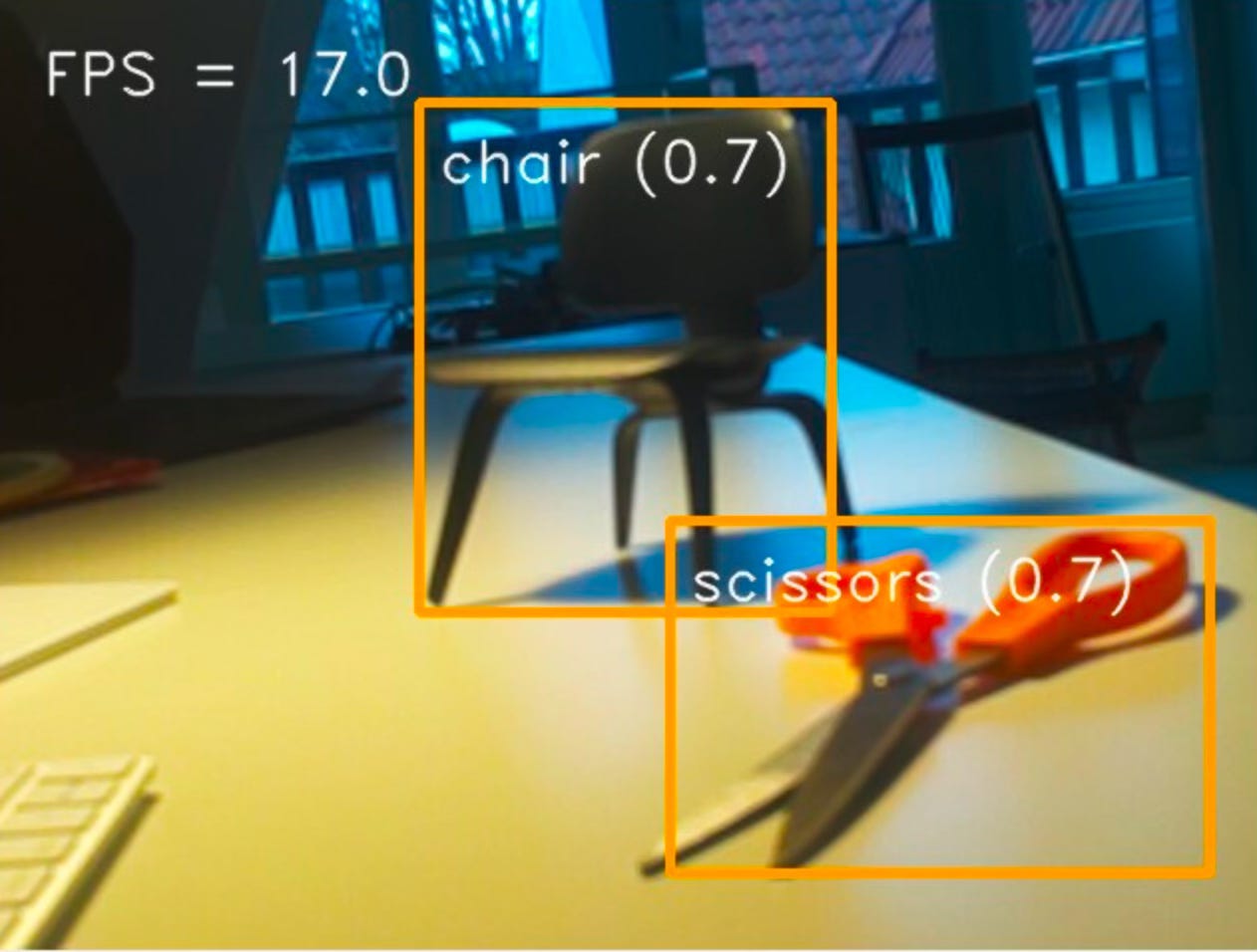
I was able to get it up and running on the RPi 5 (with a few hitches). And guess what? I am now getting about 17 fps for object detection as you can see in the capture below. The challenge I ran into is that the example code they provide uses openCV’s camera capture method:
cap = cv2.VideoCapture(camera_id)
success, image = cap.read()for capturing an image from the camera. But apparently this method only works with USB cameras. I’m using a regular Pi Camera (non-USB) so I had to adapt their code to use the picamera2 module.
picam2 = Picamera2()
image = picam2.capture_array()After some optimisation work (getting rid of as much open CV stuff as I could), I was able to get the speed up from an initial 14.5 fps to about 17 fps (640x480).
Here’s the code I ended up with:
| # Copyright 2023 The MediaPipe Authors. All Rights Reserved. | |
| # | |
| # Licensed under the Apache License, Version 2.0 (the "License"); | |
| # you may not use this file except in compliance with the License. | |
| # You may obtain a copy of the License at | |
| # | |
| # http://www.apache.org/licenses/LICENSE-2.0 | |
| # | |
| # Unless required by applicable law or agreed to in writing, software | |
| # distributed under the License is distributed on an "AS IS" BASIS, | |
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |
| # See the License for the specific language governing permissions and | |
| # limitations under the License. | |
| """Main scripts to run object detection.""" | |
| # Adapted from the following by Philip van Allen, December 2023 | |
| # https://github.com/googlesamples/mediapipe/blob/main/examples/object_detection/raspberry_pi/detect.py | |
| # obtain the efficientdet.tflite model from here | |
| # https://developers.google.com/mediapipe/solutions/vision/object_detector/index#models | |
| import argparse | |
| import sys | |
| import time | |
| import cv2 | |
| import mediapipe as mp | |
| import numpy as np | |
| from mediapipe.tasks import python | |
| from mediapipe.tasks.python import vision | |
| from utils import visualize | |
| from picamera2 import Picamera2 | |
| # Global variables to calculate FPS | |
| COUNTER, FPS = 0, 0 | |
| START_TIME = time.time() | |
| def run(model: str, max_results: int, score_threshold: float, width: int, height: int) -> None: | |
| """Continuously run inference on images acquired from the camera. | |
| Args: | |
| model: Name of the TFLite object detection model. | |
| max_results: Max number of detection results. | |
| score_threshold: The score threshold of detection results. | |
| # camera_id: The camera id to be passed to OpenCV. | |
| width: The width of the frame captured from the camera. | |
| height: The height of the frame captured from the camera. | |
| """ | |
| picam2 = Picamera2() | |
| picam2.configure(picam2.create_preview_configuration(main={"format": 'RGB888', "size": (width, height)})) | |
| picam2.start() | |
| # Visualization parameters | |
| row_size = 50 # pixels | |
| left_margin = 24 # pixels | |
| text_color = (255, 255, 255) # white | |
| font_size = 1 | |
| font_thickness = 1 | |
| fps_avg_frame_count = 10 | |
| detection_frame = None | |
| detection_result_list = [] | |
| def save_result(result: vision.ObjectDetectorResult, unused_output_image: mp.Image, timestamp_ms: int): | |
| global FPS, COUNTER, START_TIME | |
| # Calculate the FPS | |
| if COUNTER % fps_avg_frame_count == 0: | |
| FPS = fps_avg_frame_count / (time.time() - START_TIME) | |
| START_TIME = time.time() | |
| detection_result_list.append(result) | |
| COUNTER += 1 | |
| # Initialize the object detection model | |
| base_options = python.BaseOptions(model_asset_path=model) | |
| options = vision.ObjectDetectorOptions(base_options=base_options, | |
| running_mode=vision.RunningMode.LIVE_STREAM, | |
| max_results=max_results, score_threshold=score_threshold, | |
| result_callback=save_result) | |
| detector = vision.ObjectDetector.create_from_options(options) | |
| # Continuously capture images from the camera and run inference | |
| while True: | |
| original_image = picam2.capture_array() | |
| # Convert the image from BGR to RGB as required by the TFLite model. | |
| rgb_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB) | |
| mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb_image) | |
| # Run object detection using the model. | |
| detector.detect_async(mp_image, time.time_ns() // 1_000_000) | |
| # Show the FPS | |
| fps_text = 'FPS = {:.1f}'.format(FPS) | |
| text_location = (left_margin, row_size) | |
| cv2.putText(original_image, fps_text, text_location, cv2.FONT_HERSHEY_DUPLEX, | |
| font_size, text_color, font_thickness, cv2.LINE_AA) | |
| if detection_result_list: | |
| # print(detection_result_list) | |
| original_image = visualize(original_image, detection_result_list[0]) | |
| detection_frame = original_image | |
| detection_result_list.clear() | |
| if detection_frame is not None: | |
| cv2.imshow('object_detection', detection_frame) | |
| # Stop the program if the ESC key is pressed. | |
| if cv2.waitKey(1) == 27: | |
| break | |
| detector.close() | |
| cv2.destroyAllWindows() | |
| def main(): | |
| parser = argparse.ArgumentParser( | |
| formatter_class=argparse.ArgumentDefaultsHelpFormatter) | |
| parser.add_argument( | |
| '--model', | |
| help='Path of the object detection model.', | |
| required=False, | |
| default='efficientdet.tflite') | |
| parser.add_argument( | |
| '--maxResults', | |
| help='Max number of detection results.', | |
| required=False, | |
| default=5) | |
| parser.add_argument( | |
| '--scoreThreshold', | |
| help='The score threshold of detection results.', | |
| required=False, | |
| type=float, | |
| default=0.25) | |
| # Finding the camera ID can be very reliant on platform-dependent methods. | |
| # One common approach is to use the fact that camera IDs are usually indexed sequentially by the OS, starting from 0. | |
| # Here, we use OpenCV and create a VideoCapture object for each potential ID with 'cap = cv2.VideoCapture(i)'. | |
| # If 'cap' is None or not 'cap.isOpened()', it indicates the camera ID is not available. | |
| # parser.add_argument( | |
| # '--cameraId', help='Id of camera.', required=False, type=int, default=0) | |
| parser.add_argument( | |
| '--frameWidth', | |
| help='Width of frame to capture from camera.', | |
| required=False, | |
| type=int, | |
| default=1280) | |
| parser.add_argument( | |
| '--frameHeight', | |
| help='Height of frame to capture from camera.', | |
| required=False, | |
| type=int, | |
| default=720) | |
| args = parser.parse_args() | |
| run(args.model, int(args.maxResults), | |
| args.scoreThreshold, args.frameWidth, args.frameHeight) | |
| if __name__ == '__main__': | |
| main() |